안녕하세요
오늘은 python으로 데이터 분석을 할 때 주로 사용하는 scikit-learn(사이킷런) 패키지 중 model_selction 모듈에서 train_test_split 함수에 대해 정리해 보았습니다.
scikit-learn(사이킷런) 패키지를 호출할 때는 import sklearn 으로 사용한다. 왜 scikit-learn을 sklearn으로 쓰는지는 궁금한데 이유를 찾을 수는 없었습니다. 에스케이런? 스크런? 아니고 사이킷럿입니다. 그냥 외워서 씁시다..
우선 왜 train_test_split 을 사용하는지에 설명해 보겠습니다. 용어 그대로 학습용과 테스트용으로 데이터를 분리하는 것입니다. 데이터 분석은 내가 이미 결과를 아는 데이터에서 어떤 경향을 찾아내서 새로운 데이터가 들어왔을 때 예측하는 것을 주로 하는데요. 내가 가진 데이터에서 예측하는 모델을 만드는데 이것이 얼마나 정확하게 동작하는지 어떻게 확인할 수 있을까요? 방법은 처음부터 학습용과 테스트용으로 나누어서 학습용으로 모델을 학습시키고 이미 답을 아는 테스트 데이터를 모델로 예측한 결과를 정답과 비교해서 정답율을 성능으로 보는 것입니다. 학습할 데이터에서 따로 떼어서 성능을 평가하는 용도로 사용하므로 val 데이터라고 명칭 해서 사용하기도 합니다. (데이터 분석 대회에서 최종적으로 답을 예측해서 제출해야 되는 test 데이터를 제공하는데요 위에서 말한 테스트용과의 차이점은 정답을 아느냐 모르느냐 인 거죠. 그래서 예측한 결과를 제출하면 출제자가 score를 측정해서 순위를 매겨주죠.)
train_test_split 사용 방법에 대해 알아보겠습니다. 그 전에 학습 데이터에는 독립변수와 종속변수가 존재하는데요 쉽게 설명하면 독립변수는 결과에 영향을 주는 인자들이라고 생각하고 종속변수는 결과라고 생각 할 수 있습니다. 데이터 분석을 할 때 주로 x 데이터를 독립변수, y를 종속변수로 쓰더라고요. 그래서 train_test_split을 할 때 변수 데이터(x)와 정답 데이터(y)를 입력으로 줍니다. 그리고 파라미터들이 있는데요. 주로 사용하는 것만 설명드리면, test_size를 설정할 수 있습니다. 기본값은 0.25로 25%를 의미합니다. random_state는 호출할 때마다 동일한 데이터 세트로 분리하기 위해서 부여하는 난수 값입니다. 아무 숫자나 입력해서 사용합니다.
실습을 해보기 위해서 간단한 train 데이터를 만들어 보았습니다. 너무 의미 부여 하지 마세요 막 작성했습니다. ㅋㅋ
| 이름 | 야근 시간 (낮음:0~1: 높음) |
업무 스트레스 지수 (낮음:0~1:높음) |
급여 만족도 (불만:0~1:만족) |
퇴사 여부 (0:No, 1:Yes) |
| 0. 김대리 | 0.5 | 0.3 | 0.7 | 0 |
| 1. 최과장 | 0.4 | 0.1 | 0.6 | 0 |
| 2. 김사원 | 0 | 0.9 | 0 | 1 |
| 3. 이차장 | 0.7 | 0.5 | 0.2 | 0 |
| 4. 유대리 | 0.3 | 0.2 | 0.5 | 0 |
| 5. 박과장 | 0.2 | 0.4 | 0.1 | 1 |
sample.csv 파일로 만들고 pd.read_csv 하겠습니다.
import pandas as pd
df = pd.read_csv('sample.csv')from sklearn.model_extration import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.iloc[:,1:4],df.iloc[:,4],
test_size = 0.2, random_state = 11)독립변수를 야근시간, 업무 스트레스 지수, 급여 만족도, 종속변수를 퇴사 여부로 사용하였는데 dataframe에서 불러오는 방법이 여러 가지가 있는데 우선 iloc을 써서 행, 열을 지정해서 사용해 봤습니다. 행을 : 로 모두를 선택했고, 1:4는 1열에서 3열까지를 4는 4열을 선택하여 사용했습니다. 열 이름을 바로 사용할 수도 있는데요 예를 들면 df[['야근 시간', '업무 스트레스 지수', '급여 만족도']], df['퇴사 여부'] 와 같이 사용할 수도 있습니다. 띄어쓰기가 열 이름에 포함되어 있는 것도 보아야 되서 df.columns로 열 이름을 확인해서 사용하시면 좋을 것 같습니다.
나눠진 결과를 확인해 보겠습니다.
X_train
y_train
X_test
y_test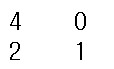
학습 데이터 총 6개 중 test_size 를 20 퍼센트로 지정했기 때문에 train 4개, test 2개가 분리되는 것을 볼 수 있습니다. 그리고 순서가 섞여 있는 것을 볼 수 있는데요 파라미터 중 shuffle 이 기본 True로 데이터를 섞어서 나눠지는 것을 확인할 수 있었습니다.
오늘은 sklearn.model_selection.train_test_split 함수에 대해 여기까지 알아보겠습니다.
감사합니다.
'Work & Study' 카테고리의 다른 글
| [데이터 분석 스터디] 데이터 전처리 (pandas.DataFrame) _null 값 (0) | 2023.04.11 |
|---|---|
| [영어 공부] 2일차 - what is your hobby? (0) | 2023.03.26 |
| [영어 공부] 1일차 - What is your favorite food? (0) | 2023.03.20 |
| [데이터 분석 스터디] sklearn.preprocessing.OneHotEncoder (0) | 2023.03.17 |

